Door de redactie
Over de opkomst van generatieve AI in de kunstsector is al veel gezegd en geschreven. Vaak lopen de meningen en de gemoederen sterk uiteen, van AI-knuffelaars aan het ene uiterste van het spectrum tot de AI-vergruizers aan het andere. Feit is dat we niet meer om AI heen kunnen. Maar hoe verhoud je je tot die onstuitbare opkomst van een even concreet als ongrijpbaar fenomeen als AI?
De redactie van Fantasize is ook op zoek naar antwoorden en probeert in gesprekken op de redactie, met anderen en via artikelen haar eigen standpunt te bepalen. Het jaarthema ‘Maakbaar’ biedt daarbij de handvatten om dit onderwerp (met zesvingerige tentakels) bij de lurven te grijpen.
In een viertal artikelen, die de komende weken zullen verschijnen, gaan we dieper in op verschillende aspecten die er aan AI kleven. In dit eerste artikel gaan we terug naar de Middag van het Fantastische Boek, geven we een samenvatting van de discussie die daar over AI werd gevoerd en leggen we het verschil uit tussen ‘gewone’ AI en generatieve AI, zoals ChatGTP en Mid Journey.
In artikel 2 pakken we de draad op waar die in Utrecht is blijven liggen en bespreken we de invloed van generatieve AI op de maatschappij en de ethiek rond AI aan de hand van enkele stellingen. In de week erna gaan we op zoek naar antwoorden op juridische vragen omtrent copyright en compensatie voor de ‘inputgevers van machine learning’.
In het vierde artikel en laatste prikkelen we de opinies weer met een stelling over de ethische schuldvraag bij medische toepassingen en komen we te spreken over de invloed van AI op onze autonomie en zelfbeschikking, waarna we naadloos overgaan op de invloed van AI op het onderwijs en onze perceptie van de werkelijkheid.
Deze reeks artikelen kwam tot stand in samenwerking met Antoni Dol, Marleen Dolman, Sandy Butchers en Charles van Wettum.

Het panel op de Middag van het Fantastische Boek
Op 25 februari 2024 werd de tweede editie van de Middag van het Fantastische Boek gehouden in Utrecht, in het prachtige voormalige postkantoor dat nu als bibliotheek dienstdoet. Een onderdeel van die middag was een discussiepanel onder leiding van Charles van Wettum. Hij en drie panelleden, te weten Antoni Dol, Marleen Dolman en Sandy Butchers, spraken over de opkomst van generatieve AI, wat dat voor gevolgen heeft voor de kunstsector en hoe kunstenaars, schrijvers en andere creatievelingen hiermee zouden kunnen omgaan. Aan de hand van enkele pittige stellingen werd ook het publiek bij de discussie betrokken.
Om een idee te krijgen waarover we het eigenlijk hebben als de kreet ‘generatieve AI’ voorbij komt, gaf Antoni Dol een korte inleiding over wat artificiële intelligentie en met name generatieve artificiële intelligentie nu eigenlijk is. In zijn presentatie (hier te vinden: https://antonidol.nl/ai) vatte hij het samen. Hieronder uitgebreid door de redactie van Fantasize.
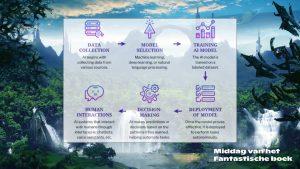
Hoe werkt AI
AI is “het vermogen van een systeem om externe gegevens correct te interpreteren, om te leren van deze gegevens en om deze lessen te gebruiken om specifieke doelen en taken te verwezenlijken via flexibele aanpassing”, aldus de definitie van Andreas Kaplan en Michael Haenlein, universitair docenten in marketing en communicatie.
Stap 1 in de werking van AI is dus: het verzamelen van externe gegevens, ofwel data. Dit kunnen foto’s zijn of teksten, waarbij elke set gegevens labels of instructies meekrijgt die het systeem helpt bij het leren (bijv. een foto van een kat krijgt het label ‘kat’ mee).
De volgende stap is dat de AI leert van deze datasets. Dit gebeurt via modellen die gebruikmaken van ‘machine learning’ en ‘deep learning’. Deep learning verwijst naar het aantal lagen waar de data doorheen gaat.
Stap 1 = data verzamelen
Stap 2 is dus het selecteren van een geschikt analysemodel.
Met behulp van neurale netwerken, met elkaar verbonden computerprocessoren, wordt de ingevoerde data ontleed en geanalyseerd. Een voorbeeld: om te bepalen of er een kat op een foto staat, breekt het model de foto op in pixels (of met de correct technische term: kernels). In de tweede laag wordt bepaald of die kernels bij een kat horen of niet. Het aantal lagen in het model maakt dit proces steeds nauwkeuriger, elke laag geeft een bepaalde set informatie mee en het model geeft een foto met een kat erop terug, als dit proces goed is uitgevoerd.
Stap 1 = data verzamelen
Stap 2 = een model selecteren
Stap 3 is dus het trainen van dat model met de methoden hierboven.

Stappen 1 tot en met 3 worden herhaald totdat er een resultaat naar tevredenheid uitkomt. Dan kan het systeem ingezet worden voor zijn taak, bijvoorbeeld het herkennen van kankercellen op een röntgenfoto of het voorspellen van het weer of voor gezichtsherkenning.
Stap 1 = data verzamelen
Stap 2 = een model selecteren
Stap 3 = het model trainen
Stap 4 is dus het inzetten van het getrainde model.
De AI in het systeem maakt voorspellingen of neemt beslissingen op basis van de getrainde patronen uit stappen 1 tot en met 3. Op die manier kan het weer voorspeld worden of kunnen vlekjes op een röntgenfoto geïnterpreteerd worden. Dit is stap 5.
Stap 1 = data verzamelen
Stap 2 = een model selecteren
Stap 3 = het model trainen
Stap 4 = het model inzetten
Stap 5 is dus het krijgen van resultaten.
De laatste stap in dit proces is de interactie tussen mens en machine. De mens voert een reeks opdrachten in, de zogenaamde prompts, en het systeem geeft een uitkomst. Om het systeem een antwoord te laten geven waarmee mensen iets kunnen (juiste grammatica, goede woorden) wordt een Large Language Model (LLM) gebruikt, een model waarmee natuurlijke talen worden begrepen en geproduceerd, en ook wordt er weer gebruikgemaakt van deep learning om de uitkomsten te verfijnen. Deze processen zijn inmiddels zo geavanceerd en vergevorderd dat het lijkt alsof een AI met je praat. Dat is niet zo, waarschuwt Antoni: het formuleert een antwoord op basis van voorspellingen en geleerde tekst.
Stap 1 = data verzamelen
Stap 2 = een model selecteren
Stap 3 = het model trainen
Stap 4 = het model inzetten
Stap 5 = resultaten krijgen
Stap 6 = mens-machinecommunicatie
Generatieve AI
Het grote verschil tussen de geprogrammeerde software die taken uitvoert en generatieve AI is dat generatieve AI uit de datasets en de geleerde patronen zélf een tekst of een afbeelding kan genereren. Dit is een stapje verder dan de ‘gewone’ systemen. Laten we de kat weer eens nemen: beide systemen krijgen een dataset met foto’s van katten te leren. Via de prompts geven we op dat we een foto van een kat willen zien. Een ‘gewoon’ programma zal dan (even kort door de bocht) de ingevoerde foto van de kat teruggeven. Een generatieve AI daarentegen heeft geleerd dat een kat uit bepaalde eigenschappen bestaat en zal een plaatje geven van een kat die hij uit die eigenschappen heeft samengesteld. Om dit niveau van ‘zelf samenstellen’ te bereiken zijn bij het inleren van het systeem miljoenen foto’s en plaatjes gebruikt en zijn de LLM-systemen veel geavanceerder.
Omdat generatieve AI zélf genereert, zich bezighoudt met activiteiten die bij de mens tot het ‘creatieve gebied’ worden gerekend, zijn de consequenties veel ingrijpender. Daarom is er zoveel commotie rondom AI.

Stelling 1: AI is creatief
Nu het publiek het proces achter AI een beetje begrijpt, is het tijd voor de eerste stelling: AI is creatief. Antoni vindt van wel, omdat het hem resultaten heeft gegeven die hijzelf niet zou hebben kunnen bedenken. Hij geeft een voorbeeld uit zijn eigen werk, waarin een bepaald buitenaards muziekinstrument voorkomt.
Het publiek slaat meteen aan op deze stelling en van diverse kanten klinkt de vraag ‘wat is creativiteit dan?’ Een terechte vraag, waarop meteen argumenten van sciencefictionliefhebbers te horen zijn dat in de fantasyhoek de creativiteit ver te zoeken is omdat er zo veel “Tolkien-klonen” worden geschreven, iets wat volgens diezelfde sciencefictionliefhebbers bij sciencefiction “uiteraard” totaal anders is, omdat daar soms rigoureus “out of the box” wordt gedacht. Eén persoon verwoordde het zo: “Creativiteit is gewoon een random afwijking op een standaard.” En dat is precies wat AI ook kan: een willekeurige afwijking zijn op een standaard. Niet echt een rooskleurig beeld van wat creativiteit is en de aanwezigen, velen zelf hobbymatige of professionele creatievelingen, verdedigen zich door te zeggen dat het gaat om het creatieve proces. Het gaat om de persoonlijke ontwikkeling, om beter te worden in bepaalde vaardigheden, de “ambachtskant” van de kunst.
Sandy beaamt dit: ‘Voor veel mensen is het creatieve proces niet te vervangen door een computer, omdat AI slechts data uitpoept.’
Stelling 2: een AI-kunstenaar is ook een kunstenaar
Panelleider Charles zet de discussie op dit punt meteen in de tweede versnelling door er nog een stelling bij te nemen, die sterk gerelateerd is aan de eerste en luidt: een AI-kunstenaar is ook een kunstenaar.
‘Want’, zegt hij, ‘zou je niet kunnen zeggen dat het schrijven van een tekst in essentie ook niets meer is dan ‘data uitpoepen’? En als je zo redeneert, zou je dan niet kunnen zeggen dat het creatieve proces zit in de manier van ordenen van die data?’
Het publiek barst los. Voorstanders beroepen zich op het idee dat prompts verzinnen die een werkbaar resultaat geven net zo knap is als zelf iets tekenen of schrijven. Tegenstanders vinden dat het zelf maken meerwaarde heeft ten opzichte van, zoals Sandy het verwoordt: “het bij elkaar schrapen van data.”
Het pijnpunt van de opkomst van AI-gegenereerde beelden ligt volgens haar ook in dat bijeenscharrelen van datasets. Het is gestolen werk, waarvoor de kunstenaar geen toestemming heeft gegeven en al helemaal geen vergoeding heeft ontvangen. Het steekt haar dat de investering die zij heeft gedaan in haar kunst, nu min of meer te reproduceren is met een druk op de knop.
Antoni werpt tegen dat de oorspronkelijke plaatjes niet meer te herkennen zijn en dat wat de AI produceert “dus” uniek is en als kunst aangemerkt zou kunnen worden. Vanuit het publiek komt de opmerking dat uit experimenten blijkt dat 1 op de 10.000 gevallen er wel degelijk een bekend werk teruggevonden kan worden, al lijkt deze bewering ook weer te zijn achterhaald door nieuwe generaties AI’s.
De discussie gaat nu naar het verleden waarin nieuwe technieken oude ambachten hebben verdrongen. Charles noemt als voorbeeld de opkomst van de fotografie, die de schilderkunst bijna de das heeft omgedaan.
‘Je drukt op een knop en je hebt een plaatje,’ zegt hij. ‘Dat is toch hetzelfde principe als AI?’
Vanuit het publiek klinkt er hier en daar bevestiging, maar toch ziet de meerderheid verschil met AI. ‘Met fotografie moet je nog verstand hebben van de techniek erachter,’ zegt iemand, ‘van de belichting, enscenering, lensbediening, sluitertijd, onderwerp enzovoorts. Bij AI is het echt een druk op een knop.’
‘Ja,’ zegt een ander. ‘Fotografie is een eigen kunstvorm geworden, daar voel je de ziel van de kunstenaar nog in. Dat is volledig weg bij die AI-gegenereerde troep.’
Maar de ontwikkeling van AI gaat razendsnel en wat AI nu nog niet kan, kan het morgen misschien wel. Gloort er een nieuwe kunstvorm aan de horizon?
Stelling 3: in een digitaal tijdperk is copyright een achterhaald begrip
Charles vat de discussie tot nu toe samen en stelt voor om net voor de tijd op is, nog een derde punt aan te stippen, namelijk het juridische aspect. De derde stelling van die dag is: in een digitaal tijdperk is copyright een achterhaald begrip.
‘Nou,’ zegt Sandy tegen Charles. ‘Hoe zou jij het vinden als ik een van jouw boeken van tafel pluk, dit overschrijf en mijn eigen naam eronder zet? Vind je dat oké?’
Zowel Charles als het publiek moet lachen om deze opmerking en de reactie impliceert dat copyright er nog altijd toe doet. Antoni plaatst daar vraagtekens bij, want waarom is een digitale foto wel een product onder copyright en een door AI gegenereerd beeld niet?
Marleen probeert helderheid te geven in deze kwestie door het een en ander uit te leggen over de juridische kaders. Hierop komen we in een later artikel uitgebreid terug.
Charles moet het gesprek beëindigen en vanuit het publiek komen teleurgestelde geluiden.
Volgende week pakken we de draad op waar die in Utrecht is blijven liggen en zal het panel en de redactie van Fantasize dieper ingaan op ethiek en de invloed van AI op onze samenleving.
Bronnen:
Antoni’s presentatie
Wikipedia Kunstmatige Intelligentie
Wikipedia Neuraal netwerk
Diepgaande uitleg generatieve AI
Makkelijke uitleg over AI
Over datadiefstal
De Correspondent: Iedereen heeft het over kunstmatige intelligentie, maar wat ís het?
Refik Anadol – dynamische kunst met AI
© 2020 – 2026 Fantasize, Antoni Dol, Marleen Dolman, Charles van Wettum & Sandy Butchers